


Kubernetes, sometimes shortened to k8s (losing the internal 8 letters) or kube, has its name rooted in ancient Greek meaning Helmsman. Like the person that steers a ship, Kubernetes takes the decisions needed to orchestrate containers on a cluster.
Kubernetes
Kubernetes is a container orchestrator to provision, manage, and scale applications, allowing to manage the life cycle of containerized applications in a cluster of (worker) nodes.
The declarative model of Kubernetes allows the user to provides the desired state and infrastructure resources, such as Volumes, Networks, and Secrets.
Kubernetes deploys containers, Linux processes running on a isolation on Linux, using a small part of the resources to avoid the duplication of operating system like in full virtualisation.
Architecture
Kubernetes uses a data store (etcd) at its core. The declarative model is stored in the data store as objects, for example upon reception of a request. This information change is watched and delegated to Controllers to take action, then react to the model and attempt to take action to achieve the desired state. The power of Kubernetes is in its simplistic model.
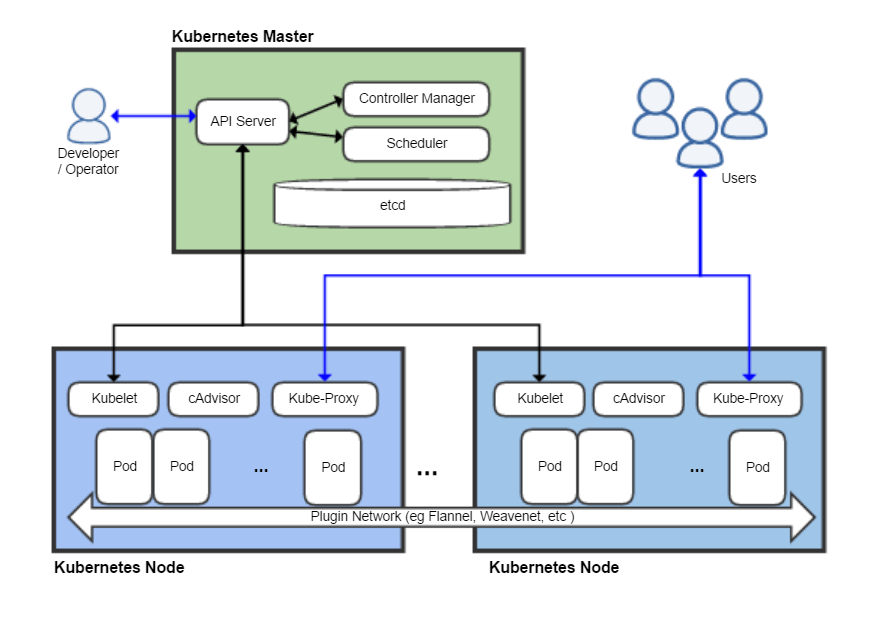
The API server is a simple HTTP server handling create/read/update/delete (CRUD) operations on the data store. Controllers identify change made, action them, and are responsible for instantiating the actual resource represented by any Kubernetes resource.
Resources Model
Kubernetes infrastructure defines a resource for every purpose, and each resource is monitored and processed by a Controller. Some of the common resources are listed below:
- Config maps: holds configuration data for pods to consume
- Daemon sets: ensures that each node in the cluster runs this pod
- Deployments: defines a desired state of a deployment object
- Events: provides life cycle events on pods and other deployment objects
- Endpoints: allows an inbound connections to reach the cluster services
- Ingress: a collection of rules that allows inbound connections to reach the cluster services
- Jobs: creates one or more pods and when they complete successfully, the job is marked as completed
- Node: a worker machine in Kubernetes
- Namespaces: multiple virtual clusters backed by the same physical cluster
- Pods: the smallest deployable units of computing that can be created and managed in Kubernetes
- Persistent volumes: provides an API for users and administrators to abstract details about how storage is provided from how it is consumed
- Replica sets: ensures that a specified number of pod replicas are running at any given time
- Secrets: holds sensitive information, such as passwords, OAuth tokens, and SSH keys
- Service accounts: provides an identity for processes that run in a pod
- Services: an abstraction that defines a logical set of pods and a policy by which to access them, sometimes called a microservice
- Stateful sets: the workload API object that manages stateful applications
Applications Health
Kubernetes uses availability checks (liveness probes) to know when to restart a container. For example, liveness probes can catch a deadlock where an app is running but be unable to make progress. Restarting a container in such a state can help to make the app more available despite the bugs.
Also, Kubernetes uses readiness checks to know when a container is ready to start accepting traffic. A pod is considered ready when all of its containers are ready. One use of this check is to control which pods are used as back ends for services. When a pod is not ready, it is removed from the load balancers.